【第46回】ロータス博士のWinActor塾~文字列操作Ⅲ


前回に引き続き「比較」の文字列操作について学んでいくぞ。
既に前方一致と後方一致は覚えたじゃろう。
次は数値と部分・全体の一致について教えよう。
前回の記事はこちら。


新しいライブラリを知れば知るほど
作れるシナリオの幅が広がりますね!
今回もお願いしますよ博士!
なんか最近やる気がすごいのう。
できることが増えると楽しくなってくるもんじゃ。
その調子で勉強に励むのじゃぞ!

あ、勉強って単語を聞いたら急にやる気が・・・
数値大小比較(Dbl精度)
数値の比較について
このライブラリはカテゴリとしては文字列比較に入っていますが
比較を行う際には、数値同士として処理されます。
比較結果は「等しい」「大きい」「小さい」の3パターンとなります。
数値1と数値2を比較した場合、次のような結果が変数に返されます。
| 比較結果 | 返される値 |
| 数値1 = 数値2 | 0 |
| 数値1 > 数値2 | 1 |
| 数値1 < 数値2 | -1 |
Dbl精度とは
Dblは倍精度浮動小数点数型を示すDoubleの略です。読み方はダブルです。
WinActorには変数の型が存在しないため、実際に数値の大きさなどを意識する必要はほとんどありませんが
このライブラリは、Double型相当のサイズの数値の比較が可能ということを示しています。
なんだかよくわからないんですけど
具体的にどのくらいの大きさまで比較できるんですか?
-1.79769313486232E308 ~ -4.94065645841247E-324 (負の値)
4.94065645841247E-324 ~ 1.79769313486232E308 (正の値)
の範囲じゃな。
え、ちょっと、いきなり呪文の詠唱はやめてください。
えーと・・・数値に小数点がありますけど、もしかして結構小さい数値なんですか?
しかもEってなんですか?
呪文て・・・ここはあまり覚えなくても良いところなのじゃが・・・。
まあ、せっかくじゃから詳しく教えよう。
Eは10のべき乗を表します。
例えば 1E3 であれば 103 = 1000 となります。
| 表記 | 意味 | 数値 |
| 1E2 | 1 × 102 | 100 |
| 1E3 | 1 × 103 | 1000 |
| 1E4 | 1 × 104 | 1万 |
| 1E5 | 1 × 105 | 10万 |
| 1E6 | 1 × 106 | 100万 |
| 1E7 | 1 × 107 | 1000万 |
| 1E8 | 1 × 108 | 1億 |
| 1E9 | 1 × 109 | 10億 |
| 1E10 | 1 × 1010 | 100億 |
| 1E11 | 1 × 1011 | 1000億 |
| 1E12 | 1 × 1012 | 1兆 |
Eの前の数字が1でない場合は、その数で掛け算を行います。
例えば 1.5E3 であれば 1.5 × 103 = 1500 となります。
先ほどの博士が言っていた1.79769313486232E308は
1.79769313486232 × 10308 となります。

10の308乗・・・もしかしてなんですけど
これ、とんでもない数値になりますよね。
-324乗も忘れてはならんぞ。小数点以下もとんでもないところまで比較できるのじゃ。
つまり我々が気にする必要もないほどに高精度ということじゃな。
うーん、とりあえず気にしなくていい
ということはわかりました!

気にする必要はないとは言ったし、実際その通りなのじゃが・・・
その返事はなんだか府に落ちんな・・・
使い方
ライブラリは下記の階層にあります。
NTTATライブラリ > 06_文字列比較 > 数値大小比較(Dbl精度)
このライブラリは、前方一致比較のように分岐ノードがセットではありません。
使用する際は分岐ノードを配置しましょう。
プロパティは以下のようになっています。
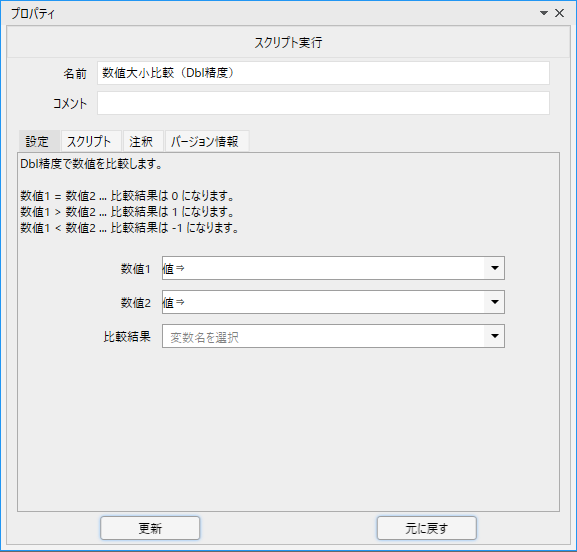
「数値1」と「数値2」に指定した数値同士を比較して、結果を「比較結果」変数に格納します。
格納される比較結果は3通りです。もう一度確認してみましょう。
| 比較結果 | 返される値 |
| 数値1 = 数値2 | 0 |
| 数値1 > 数値2 | 1 |
| 数値1 < 数値2 | -1 |
例えば「数値1」が「数値2」より大きい場合に何か処理をしたい、といったときには
このライブラリのすぐ後に「分岐」ノードを配置し、次のように条件を設定します。
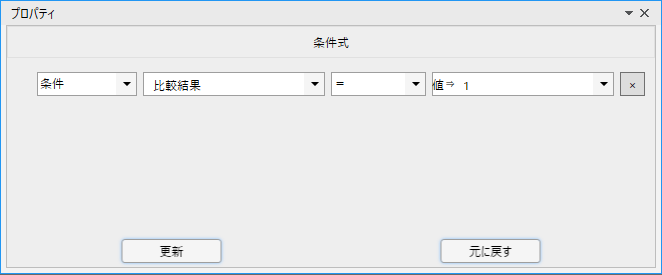
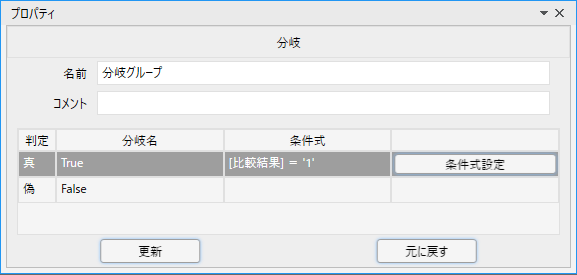
※プロパティの「比較結果」には「比較結果」という名前の変数を指定しています
こうすることで、数値1が数値2より大きい場合に比較結果に1が格納され、分岐のTrue側の処理が実行されます。
文字列比較
文字列比較について
このライブラリは、単純に2つの文字列同士が全て一致しているかどうかを判定するために使用します。
分岐ノードでの条件設定だけでも文字列が等しいかどうかを判定できるため、必ずしもこのライブラリを使用する必要はありません。
しかしこのライブラリの判定は若干特殊で、比較結果が数値比較のように3パターンになります。
| 比較結果 | 返される値 |
| 文字列1 = 文字列2 | 0 |
| 文字列1 > 文字列2 | 1 |
| 文字列1 < 文字列2 | -1 |
ほとんどの場合、2つの文字列が等しいかそうでないかだけで判定するため
返される値が0か0以外かで分岐させるのが一般的です。
そのため、よほど特殊なことが無い限り1や-1を使うことはありません。
2つの文字列が等しいかどうかを知りたければ
素直に分岐ノード1つで済ませるのが良いかも知れんな。
でも1や-1の判定が気になります。
数値ならまだしも、文字列の比較に大小があるなんて。
そうじゃな。使うことはなくても気になってしまう気持ちはわかる。
実はこのライブラリは文字コードというもので判定を取っておるのじゃ。
文字コードとは、コンピュータで文字を処理するために文字に割り振られた番号のようなものです。
文字コードにも種類があり、番号の振られ方はその種類によって異なります。
VBSのStrComp関数はASCIIコード・JISコードが使用されています。
例えばShift-JISコードでは「ア」は 8341 (16進数)、「イ」は 8343 という数値になります。
この2つの文字を数値として比較すると 8341 < 8343 (ア < イ)となります。
このライブラリではこのようにして文字列を文字コードの数値で判別し、大小を比較します。
博士、僕わかりましたよ。
この文字コードとやらで大小を比較することは
僕の作るシナリオに必要無いだろうということが。
まあ、文字コードの大小を調べるなんてのはよほどのレアケースじゃろうな。
実際に使うことはないじゃろうが、豆知識として覚えておくと良いぞ。
使い方
ライブラリは下記の階層にあります。
NTTATライブラリ > 06_文字列比較 > 文字列比較
このライブラリにも分岐ノードはありません。
使用する際は分岐ノードを配置しましょう。
プロパティは次のようになっています。
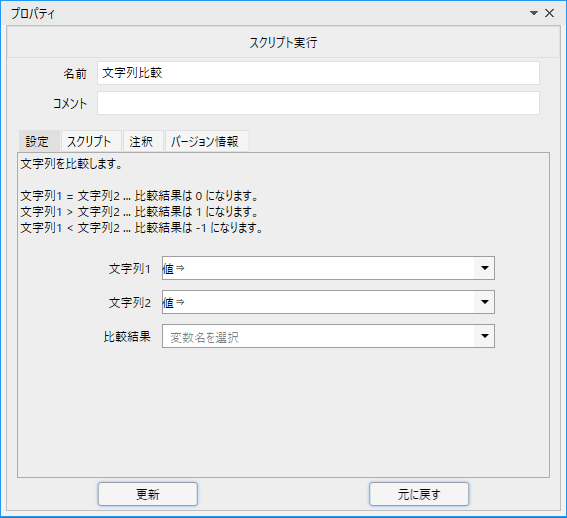
「文字列1」と「文字列2」を比較した結果が「比較結果」変数に格納されます。
主な利用方法は数値比較と同様です。
部分一致比較
部分一致とは
部分一致はその名の通り、一部分だけを見たときに一致するところがあるかどうかで判定を行います。
ではこちらの文字列で確認してみましょう。
今日も元気にがんばろう
この文字列に対して「元気に」というキーワードで比較を行うと
今日も元気にがんばろう
元気に
一致する部分があったため結果はtrueとなります。
また、前方一致や後方一致のように、文字列の中のどの位置であるかは関係ありません。
文字列の最初にあっても、最後にあっても、真ん中あたりにあっても
キーワードに一致する部分がどこかに存在すればtrueとなります。
使い方
ライブラリは下記の階層にあります。
NTTATライブラリ > 06_文字列比較 > 部分一致比較
ライブラリは下図のように、分岐ノードとセットになって配置されます。
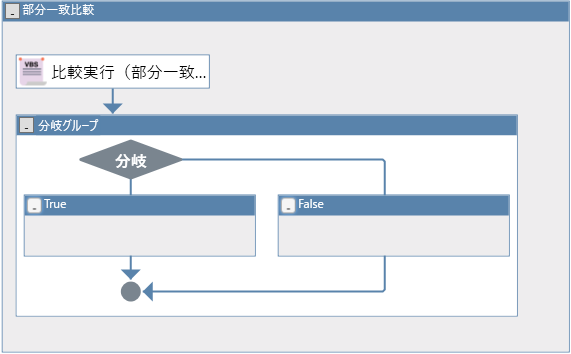
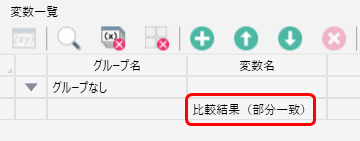
また、このライブラリも前方一致などの時と同じのように
配置すると「比較結果(部分一致)」という変数が自動的に作成され、分岐ノードに利用されます。
プロパティは以下の通りです。
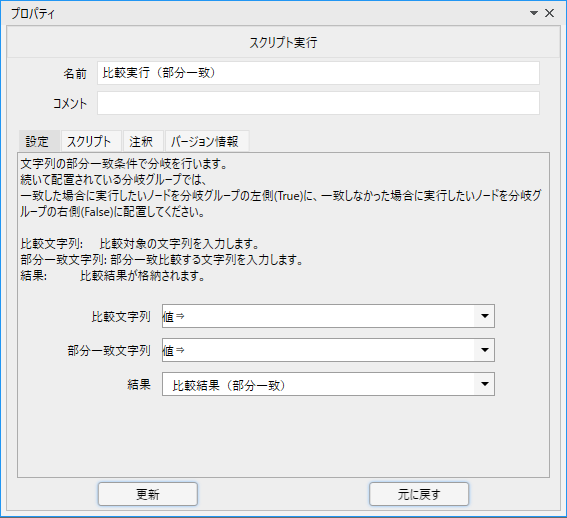
「比較文字列」に設定した文字列に対して「部分一致文字列」に設定したキーワードでチェックを行います。
「比較文字列」の中にキーワードが含まれていればtrue、そうでなければfalseが返されます。
部分一致はとても簡単で使い勝手も良い!
これは是非とも覚えておこう!
比較だけでもこんなにたくさんあるんですね。
でもまだまだ文字列操作っていっぱいありましたよね・・・。
全部覚えられるかなあ。
比較に関するものはこれで全部じゃな!
なに、安心せい。めったに使わないものは紹介程度にするつもりじゃ。
そのかわり、重要度の高いものはしっかり覚えてもらうぞ!

そういうことなら頑張れそうです!
文字列操作は直感でなんとかなりそうなのが多いですからね!
よし!では今回はここまで!
では一通り終わったら試験でもやるかの?
・・・

関連記事こちらの記事も合わせてどうぞ。

2024.11.05
【第105回】ロータス博士のWinActor塾~新しい画像マッチング画面
")
2024.09.27
【第104回】ロータス博士のWinActor塾~ガイド利用シナリオ(作成編)
")
2024.09.10